Fundamentals of Fast Bulk IO
1. IO buffers
Synchronous access
The simplest way for a program to read (or to write) a chunk of file is to allocate a buffer for the data, issue a request to the OS and then sit there and wait until the request is fullfiled. Once the data is in (or out), proceed to the next step.Since the program effectively stops running while waiting for the request to complete, this is called a synchronous IO.
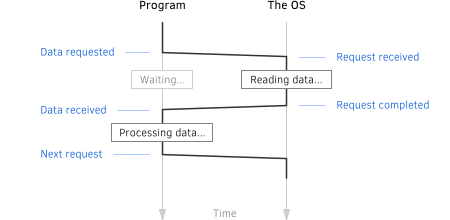 It is very simple to implement, it keeps the code
nice and tidy and it is widely used in software
for reading/writing files.
It is very simple to implement, it keeps the code
nice and tidy and it is widely used in software
for reading/writing files.
However, if we want to read/write fast, we can do significantly better.
Asynchronous access
Instead of waiting for a request to complete, a program can make a note that the request is pending and move on to doing other things. Then, it will periodically check if the request is done and when it is, it will deal with the result.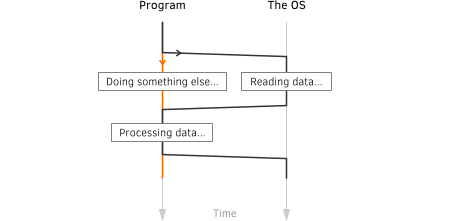 Since we are no longer blocking around an IO
request, this is called an asynchronous IO.
Since we are no longer blocking around an IO
request, this is called an asynchronous IO.
Note that in terms of the IO performance, it is so far exactly the same as the synchronous case.
Asynchronous, multiple buffers
Now that we are free to do something else while our request is pending, what we can do is submit another request. And then, perhaps, few more, all of which will be pending and queued somewhere in the guts of the OS.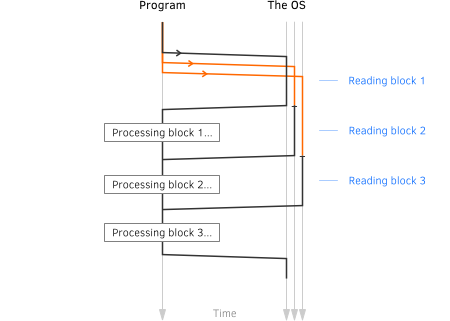 What this does is it ensures that once the OS
is done with one request, it will immediately
have another one to process.
What this does is it ensures that once the OS
is done with one request, it will immediately
have another one to process.
This eliminates idling when reading/writing data from the storage device, so we have data flowing through the file stack continuously.
Knowing when to stop
It may seem that if we just throw a boatload of requests at the OS, it should allow us to go through a file as quickly as possible.However there's really no point in having too many requests in a queue, because it simply doesn't give us any faster processing.
What we need is to merely make sure the request queue is never empty, so if we can achieve that with as few requests as possible, we'll have the fastest processing rate and the lowest memory usage.
2. IO buffer size
Another question is how much data to request in one
go.
If we ask for too little, the OS may end up reading more than asked for and then trimming the result to fit it into our buffer.
For example, NTFS defaults to 4KB cluster size on desktop versions of Windows, so asking for a smaller chunk is going to be wasteful.
If we ask for too much, it may translate into several requests further down the file stack and it's not likely to get us any speed gains.
If we ask for too little, the OS may end up reading more than asked for and then trimming the result to fit it into our buffer.
For example, NTFS defaults to 4KB cluster size on desktop versions of Windows, so asking for a smaller chunk is going to be wasteful.
If we ask for too much, it may translate into several requests further down the file stack and it's not likely to get us any speed gains.
3. IO mode
Buffered and unbuffered access
Windows has two principal modes for accessing files - the so-called buffered and unbuffered IO.In buffered mode all requests pass through the Cache Manager, which does just what it name implies - it tries to fulfill read requests from the cache and aggregate/delay write requests when appropriate.
In unbuffered mode requests are always fulfilled with an actual disk read/write. They still pass through the Cache Manager to expire any cached copies of same data, but this comes with less overhead than in buffered mode.
Sequential vs random access
Windows also allows programs to indicate if they are planning to work with file in a sequential manner, which happens to be an exceedingly common pattern. This is what happens when files are saved, loaded, copied and when programs are launched.* This is also a reason why CCSIO has the S in the middle - it is concerned with testing IO performance for this particular access type.
The other pattern is that of a random access. This is when a program is jumping around a file when reading or writing it. This is what database applications do, mostly.
Sequential access and the Cache Manager
Opening file for sequential IO acts as a hint to the cache manager and allows it to apply a different caching strategy.In particular, the cache manager will pre-fetch data when possible and it will also discard cached data more aggressively.
Conversely, using buffered non-sequential access for large files is a recipe for trashing the file cache. One of those "use with care" things.
In theory, this setting - declaring intended access patter - should only matter for buffered (cached) access.
In practice, it happens to have a noticeable effect on performance of the unbuffered access too, so we have to consider and test for this as well.
4. Summed up
Performance of any bulk IO operation depends on
three principle variables - the size of IO buffers,
their count and the IO mode.
Some combinations of these parameters will yield a subpar performance, while others will push the stack to its limit and deliver the best IO rate possible.
Based on what we've seen so far there's no universal recipe that works well across all device and volume types. Moreover, even looking at device classes - HDDs, SSDs, network shares, etc. - there doesn't appear to be any dominating combinations either. To each (device) its own.
That said, using larger buffers (from 512KB) and unbuffered mode seems to usually deliver rates that are within 5-10% of maximum achievable throughput.
If in doubt, test your setup with CCSIO Bench and derive your own conclusions.
Some combinations of these parameters will yield a subpar performance, while others will push the stack to its limit and deliver the best IO rate possible.
Based on what we've seen so far there's no universal recipe that works well across all device and volume types. Moreover, even looking at device classes - HDDs, SSDs, network shares, etc. - there doesn't appear to be any dominating combinations either. To each (device) its own.
That said, using larger buffers (from 512KB) and unbuffered mode seems to usually deliver rates that are within 5-10% of maximum achievable throughput.
If in doubt, test your setup with CCSIO Bench and derive your own conclusions.